In modern cloud-native environments, containers have become the backbone for running services at scale. Kubernetes, in particular, excels at orchestrating containerized applications. One common scenario in such setups is running long-lived worker processes that consume messages from a queue, such as a Symfony Messenger worker.
Pros of containerized workers:
- Scalability: Containers can be scaled horizontally by Kubernetes.
- Isolation: Each container runs its own isolated environment.
- Portability: Containers work across any environment that supports Docker or Kubernetes.
However, there are some downsides:
- Lack of lifecycle control: If a command in the container exits, the entire pod may restart.
- Signal handling: Without proper handling, Kubernetes might not gracefully shut down a container.
In environments where a worker has a time-limited lifespan, such as running Symfony Messenger workers with a --time-limit, we often encounter a scenario where the worker finishes its job and the command exits. This triggers a pod restart unless properly handled.
The Problem
Imagine the following log output from a worker running in a Kubernetes pod:
$ bin/console messenger:consume 'system_integration' --time-limit=600 -q
[OK] Consuming messages from transports "system_integration".
// The worker will automatically exit once it has been running for 600s or
// received a stop signal via the messenger:stop-workers command.
// Quit the worker with CONTROL-C.The worker completes its work after 600 seconds, which leads to the command exiting. This causes Kubernetes to think the container has failed, leading to the pod being restarted. This constant restarting is not ideal, as it creates unnecessary pod churn and potential delays in processing.
The Solution
To solve this problem, we can modify the script that runs inside the container to ensure that the worker is restarted automatically without causing a pod restart. This can be achieved by trapping termination signals and using a while loop to restart the worker when it exits.
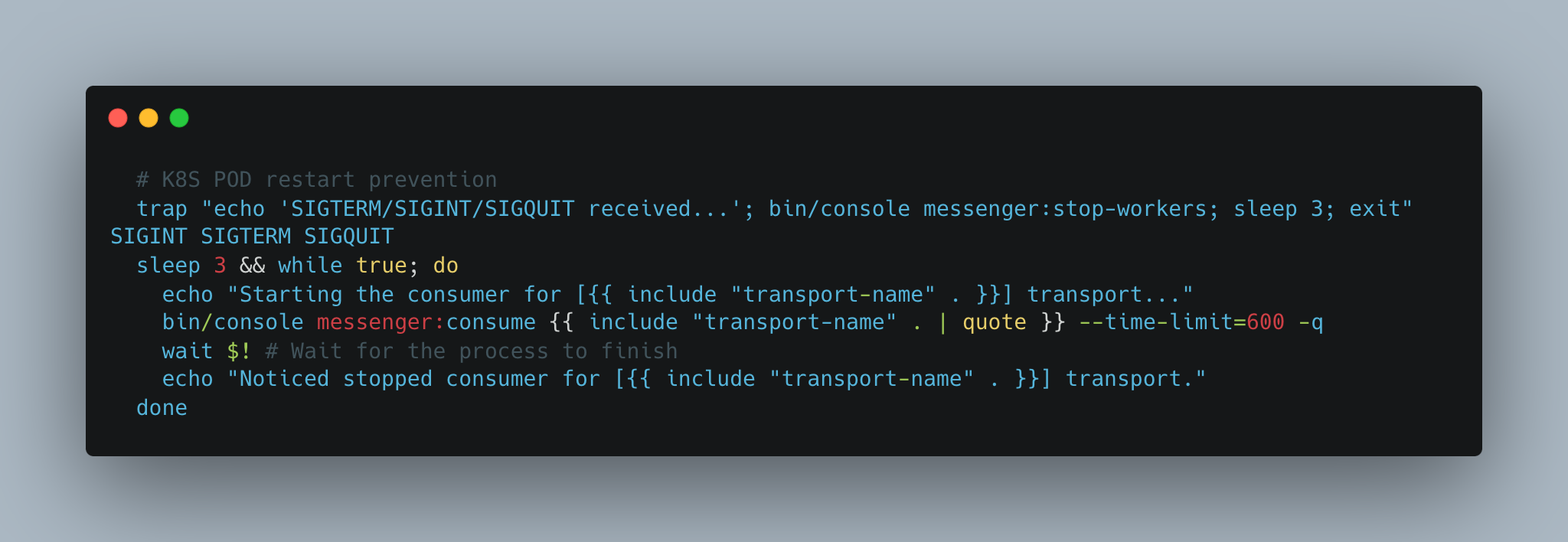
Here’s the final solution:
command:
- /bin/sh
- -c
- |
trap "echo 'SIGTERM/SIGINT/SIGQUIT received, running cleanup...'; bin/console messenger:stop-workers; sleep 3; exit" SIGINT SIGTERM SIGQUIT
sleep 3 && while true; do
echo "Starting the consumer for [system_integration] transport..."
bin/console messenger:consume 'system_integration' --time-limit=600 -q
wait $! # Wait for the worker to complete or be stopped
echo "Noticed stopped consumer for [system_integration] transport."
doneKey Benefits:
- Graceful shutdown: When the container receives signals like
SIGTERM, it runs a cleanup command (messenger:stop-workers) to stop the worker gracefully before exiting. - Continuous worker execution: The worker is wrapped in a
while trueloop, so it automatically restarts after every 600-second run without causing the pod to restart. - Signal handling: The
trapcommand ensures that signals are captured and handled, preventing the pod from being killed prematurely.
Potential Drawbacks:
- Complexity: The script introduces additional complexity in managing the worker lifecycle.
- Manual restart logic: Restarting is now controlled by the script, rather than Kubernetes, which might feel less natural in an orchestrated environment.
Alternatives
There are other ways to handle worker lifecycles and restart logic in containerized environments. Here are a few alternatives:
1. s6 Supervisor
The s6 supervisor is a lightweight process supervisor designed for containers. It can manage multiple processes within a container and handle lifecycle events like restarts and signal forwarding.
Pros:
- Built-in process supervision: Automatically handles restarting the worker without relying on shell loops.
- Graceful shutdown: s6 has native support for managing signals and cleaning up processes properly.
- Multi-process support: Can run multiple commands inside the same container.
Cons:
- Additional dependency: Requires installation and configuration of the
s6supervisor in your container. - Learning curve: It has its own scripting syntax, which may require time to master.
2. Runit
runit is another lightweight process supervision tool similar to s6. It handles process monitoring and restarting.
Pros:
- Fast and efficient: Extremely lightweight and fast, well-suited for containerized environments.
- Simple configuration: Easier to set up compared to
s6for basic use cases.
Cons:
- Single-process focus: While capable, it might not handle complex multi-process scenarios as well as
s6. - Less adoption: Not as widely adopted as other tools, meaning fewer community resources.
3. Systemd
Systemd, commonly used in many Linux distributions, can also act as a process supervisor inside containers.
Pros:
- Feature-rich: Provides comprehensive process management, logging, and signal handling.
- Built-in process control: Handles restarting and process lifecycle management out of the box.
Cons:
- Heavyweight: Overkill for containers due to its size and complexity.
- Not container-native: Not designed with containers in mind, leading to potential compatibility issues.
Conclusion
The original issue – of unnecessary pod restarts – can be solved by wrapping the worker process in a while loop and trapping termination signals. This allows the worker to restart gracefully without causing Kubernetes to restart the pod, improving both reliability and performance.
While alternatives like s6, runit, and systemd offer more structured supervision, the lightweight shell script approach is simple, effective, and easily to be integrated into existing Helm charts right away. Each solution has its pros and cons, so the choice depends on your system’s requirements and complexity.