Optimizing MySQL Queries for data synchronization script

Today I’d like to share with you an episode of MySQL queries optimization. Deploying an application that grows over time implies some refactoring for components or logic that no longer scales or becomes a bottleneck of performance for the app, which might affect at some point the health of the system. This kind of refactoring I had to deal with lately, when I started the task to improve the data synchronization script between two databases, each with a different structure for the data. We are talking about two different platforms running for the same tenant, where the data had to be replicated from the Source system and the Target system. Next, I’ll call the source System/DB Lambda, and the Target System/DB Alpha.
The issue was the ever increasing time in executing the data synchronization script, and we also started to notice the degradation of the RDBMS service.
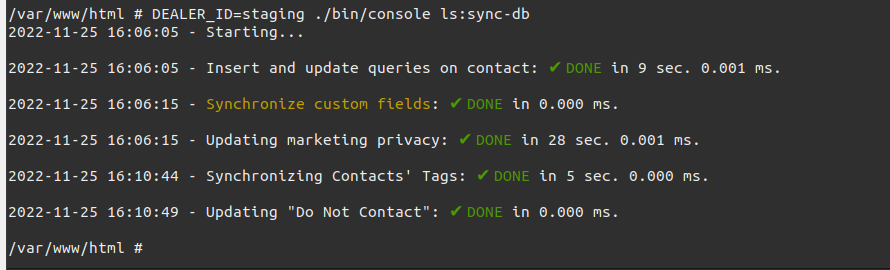
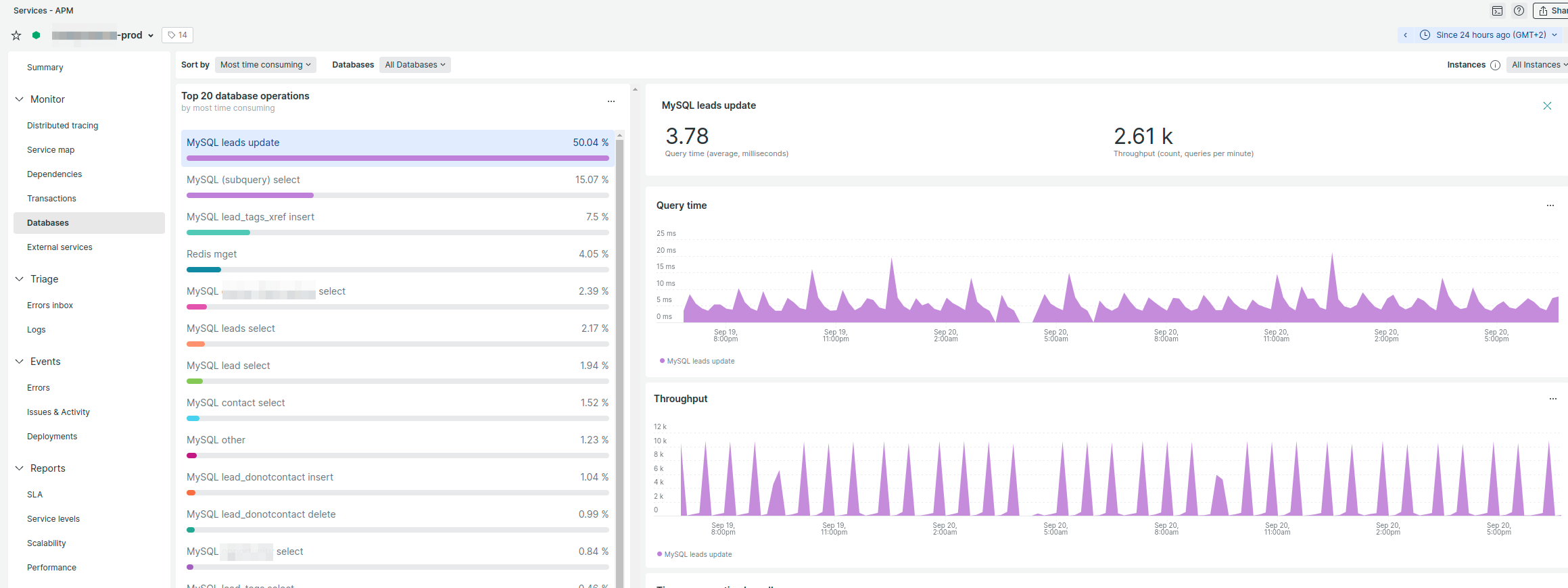
The numbers did not look well, especially when you manage a lot of tenants.
So, let’s get hands dirty and, step by step, optimize the sync queries and improve performance.
Insert and update contacts’ queries
Insert new contacts
At this step we aim to add new contact records into the Alpha DB, with only the basic, required data.
The initial query looked like this:
INSERT INTO alpha.leads (origin_id, is_published, points, date_added, date_identified)
SELECT c.id AS origin_id,
1 AS is_published,
0 AS points,
CURRENT_TIMESTAMP AS date_added,
c.created_at AS date_identified
FROM lambda.contact c
LEFT JOIN alpha.leads l ON l.origin_id = c.id
WHERE l.id IS NULL;From this query we understand that a full tables join is performed and that only some records are considered for the insertion (WHERE l.id IS NULL). The biggest issue with this query is that full tables are used for join, whereas we only need the missing records from the target DB. Since the JOIN operations are very resource intensive for large data sets, the first thing to check was to see if it’s possible to rewrite the query as such, to get rid of the JOIN part. And i ended up with this:
INSERT INTO alpha.leads (origin_id, is_published, points, date_added, date_identified)
SELECT c.id AS origin_id,
1 AS is_published,
0 AS points,
CURRENT_TIMESTAMP AS date_added,
c.created_at AS date_identified
FROM lambda.contact c
WHERE c.id NOT IN (SELECT l.origin_id FROM alpha.leads l WHERE l.origin_id IS NOT NULL)
and c.created_at >= (SELECT IFNULL(MAX(l.date_added), '2000-01-01 00:00:00') FROM alpha.leads l);The first part of the query stayed the same, down until and including the FROM line; what is below that line has drastically changed. What I did there is to filter the contacts fetched for insert, from the lambda.contact table, by eliminating the already-synced records – c.id NOT IN (SELECT l.origin_id FROM alpha.leads l WHERE l.origin_id IS NOT NULL) – but also to consider only records created after the date/time of the latest synced item – c.created_at >= (SELECT IFNULL(MAX(l.date_added), '2000-01-01 00:00:00') FROM alpha.leads l). Note that I’ve added an apparently useless condition in the first subquery of the where clause, that is WHERE l.origin_id IS NOT NULL. The reason I did this is because MySQL seems to use NULLs in a very special way. Consider the following queries, and their output inlined in a comment:
SELECT 'a' IN ('s', 'd', 'v'); # 0
SELECT 'a' IN ('s', 'd', NULL, 'v'); # <null>
SELECT 'a' IN ('s', 'd', NULL, 'v', 'a'); # 1
SELECT 'a' NOT IN ('s', 'd', 'v'); # 1
SELECT 'a' NOT IN ('s', 'd', NULL, 'v'); # <null>
SELECT 'a' NOT IN ('s', 'd', NULL, 'v', 'a'); # 0From my understanding is that for MySQL the NULLs are like placeholders that can hide any value. They are not empty data, they are missing data. That’s also the reason why for the second subquery of the filter I use a default value for when MAX(l.date_added) is NULL.
The impact of the new query: 4x improvements gain under certain conditions (staging RDBMS, dataset of 107K records in Lambda Contact DB table, going from ~8sec to ~2sec).
Note: The impact for all the queries here is measured by running the queries on a staging RDBMS – not very performant -, having source tables with relatively small amounts of data. I suppose we can safely assume that the impact on larger data sets is larger.
Sync Contacts’ data
With this query, the Contacts data gets upserted. The initial query updated all the records, no matter if the data was fresh or old:
UPDATE alpha.leads target
INNER JOIN lambda.contact c ON target.origin_id = c.id
LEFT JOIN (SELECT contact_id, region FROM lambda.contact_detail WHERE region IS NOT NULL GROUP BY contact_id) cd ON c.id = cd.contact_id
SET target.origin_id = c.id,
target.firstname = c.first_name,
target.lastname = c.last_name,
target.date_modified = CURRENT_TIMESTAMP,
target.pr_mktg_sms = 0,
target.pr_mktg_email = 0,
target.address1 = c.street,
target.address2 = c.street2,
target.zipcode = c.postal_code,
target.city = c.city,
target.state = cd.region,
target.country = c.country_codeNote: some data got truncated in this process, due to differences in the tables’ column definitions, but with the query above I’ll assume the source and target’s column types were identical.
The optimize this query I made use of the lambda.contact.updated_at and alpha.leads.date_modified columns, so the addition was a simple, yet powerful WHERE clause:
WHERE (target.date_modified is null or target.date_modified != c.updated_at);This query will insert the data for the new records, where target.date_modified is null, and will update the data for the modified records, where target.date_modified != c.updated_at.
The impact of this query on performance is almost 100%, since the data is filtered to such a small subset; we still have a join in the query, of which I could not get rid, but hey!, no more redundant data copy! ?
Remove Contacts
Sometimes, the records form the source DB get deleted (in our case it was the deduplication feature, where 2 or more contacts were merged together into a single entity, aggregating the data from the other entities), and the following query aims to remove previously added contacts to the alpha.leads table:
DELETE alpha.leads
FROM alpha.leads
LEFT JOIN lambda.contact c ON c.id = leads.origin_id
WHERE c.id IS NULL;This query seemed to run just fine, and the alternative I came with did not show any significant improvement:
DELETE
FROM alpha.leads
WHERE origin_id NOT IN (SELECT c.id from lambda.contact c)This one avoids a JOIN and seems easier to read. I brought and tested another alternative, that uses EXISTS, but that one had a tiny, but obvious performance penalty compared to the other two methods:
DELETE
FROM alpha.leads
WHERE NOT EXISTS(SELECT c.id from lambda.contact c WHERE c.id = leads.origin_id)The impact of the second query – which I choose for the simplicity to read – is negligible, so… let’s move on, to the next one.
Update Contacts’ Marketing Preferences
This is where the most improvement can be made, since the sync process is different than what we had before – it involves UPDATE queries for each “Contact communication detail” record.
/* Run and fetch data from 2 queries, for $channelType = sms, email */
SELECT
c.id AS origin_id,
cd.{$sourceColumnName} AS $targetColumnName
FROM lambda.contact AS c
INNER JOIN lambda.contact_detail AS cd ON c.id = cd.contact_id
INNER JOIN lambda.contact_privacy_preference AS cpp ON cd.id = cpp.contact_detail_id
AND cpp.preference_type = 'marketing'
AND cpp.privacy_preference_channel_type = '$channelType'
AND cpp.accepted = 'accepted'
/* and for each resultset iterate through results and sanitize some data (if needed) */
/* and for each result in the resultset run a SQL update query for the target DB */The query template from above ran 2 times, for $channelType with “sms” and “email” as values. Each record of the result sets was sanitized (even if not needed in most cases), and was put into an UPDATE query and run.
The problem with this approach is… not a single one. First, bringing the data in the app is not good for long-term, when you know that the data grows continuously. Second, the more data grows, the more UPDATE queries will hit the database for each synchronization session. I cannot stretch how wrong this approach is.
The solution I had in mind was to transfer the data between the databases by a single query, then only fetch the data that has to be sanitized or altered, and perform the operations in the app, and finish by updating the sanitized entries. And this for each of “sms” and “email” contact communication channel.
UPDATE alpha.leads target
inner join (SELECT cd.contact_id AS origin_id,
cd.phone_number AS mobile
FROM lambda.contact_detail AS cd
WHERE cd.id in (SELECT cpp.contact_detail_id
FROM lambda.contact_privacy_preference AS cpp
WHERE 1
AND cpp.preference_type = 'marketing'
AND cpp.privacy_preference_channel_type = 'sms'
AND cpp.accepted = 'accepted')) source ON target.origin_id = source.origin_id
SET target.mobile = source.mobile,
target.pr_mktg_sms = 1
WHERE 1;
/* [2022-12-05 11:05:54] 7,159 rows affected in 1 s 168 ms */
UPDATE alpha.leads target
INNER JOIN (SELECT cd.contact_id AS origin_id,
cd.email AS email
FROM lambda.contact_detail AS cd
WHERE cd.id in (SELECT cpp.contact_detail_id
FROM lambda.contact_privacy_preference AS cpp
WHERE 1
AND cpp.preference_type = 'marketing'
AND cpp.privacy_preference_channel_type = 'email'
AND cpp.accepted = 'accepted')) source ON target.origin_id = source.origin_id
SET target.email = source.email,
target.pr_mktg_email = 1
WHERE 1;
/* [2022-12-05 12:19:59] 3,596 rows affected in 1 s 204 ms */With the two queries above I got 2.4 seconds, compared to the 28 seconds previously. In the new approach I missed the times that would require to update sanitized data (phone numbers with the wrong format), which is expected to be negligible – the data was fixed in the source DB once, and in the app.
Sync contacts’ tags
Similar as in the Marketing Contact Preference case, a cascade of queries are ran based on fetched data from both the Lambda DB and the Alpha DB (data sets are compared for each contact record, and new tag records are inserted using a single query per contact record).
The same result can be achieved using 2 SQL queries, gaining lots of time and implicitly CPU.
/* STEP 1: Add missing Contacts' Tags in Alpha DB */
INSERT INTO alpha.lead_tags
SELECT null, t.name
FROM lambda.tag t
WHERE 1
AND t.name not in (SELECT tag from alpha.lead_tags)
AND t.id in (SELECT ct.tag_id from lambda.contact_tag ct)
;
/* [2022-12-05 16:38:24] 1 row affected in 218 ms */
/* STEP 2: Add missing Contacts Tags' relationships in Alpha DB */
INSERT INTO alpha.lead_tags_xref
SELECT l.id, t.id
from lambda.contact_tag sourceXref
INNER JOIN lambda.tag sourceTag on sourceXref.tag_id = sourceTag.id
INNER JOIN alpha.leads l on sourceXref.contact_id = l.origin_id
INNER JOIN alpha.lead_tags t on sourceTag.name = t.tag
WHERE NOT EXISTS(SELECT x.tag_id FROM alpha.lead_tags_xref x WHERE x.tag_id = t.id AND x.lead_id = l.id)
;
/* [2022-12-05 16:38:27] 1 row affected in 247 ms */In the first query I bring all the new Contact tags from Lambda DB to Alpha DB, while in the second query I bring all the missing Contact-Tag relationships from Lambda DB to Alpha DB.
Also, in the example above, the results are for a testing scenario where 1 Tag (and implicitly its relationship with the Contact) was removed in Alpha DB. By running those queries I got the Tag back in the Alpha DB, and its relationship with the Contact restored.
The impact of this change, in the same environment, I got an improvement from ~5 seconds to ~465ms, which is another 10x improvement.
Sync Contacts’ Do-Not-Contact
In this table we keep the records with Marketing Contact Preference set with a falsey value.
The following 4 queries of the current approach were pretty straight forward:
/* Delete all the entries from the DNC */
DELETE FROM alpha.lead_donotcontact;
ALTER TABLE alpha.lead_donotcontact AUTO_INCREMENT = 1;
/* Add all the entries into DNC list, for $channel = ['sms', 'email'] */
INSERT INTO alpha.lead_donotcontact (lead_id, date_added, reason, channel)
SELECT
l.id AS lead_id,
CURRENT_TIMESTAMP AS date_added,
1 AS reason,
'$channel' AS channel
FROM alpha.leads AS l
WHERE l.pr_mktg_{$channel} = 0;This is not a sync between DBs, but rather a data representation, like a DB view.
The issue I see here is the table truncation (using the DELETE statement), then adding all the records back. So, I thought to try another method. What if I only remove the records that do not belong to this table any more, and also add only the new records that should be present here:
/* Delete entries that we can contact already, according to data sync from Lambda DB */
DELETE FROM `alpha`.lead_donotcontact
WHERE 1
AND (
(channel = 'sms' AND lead_id in (SELECT l.id FROM `alpha`.leads l WHERE l.pr_mktg_sms = 1))
OR (channel = 'email' AND lead_id in (SELECT l.id FROM `alpha`.leads l WHERE l.pr_mktg_email = 1))
);
/* Add new entries to Do-Not-Contact list, for $channel = ['sms', 'email'] */
INSERT INTO alpha.lead_donotcontact (lead_id, date_added, reason, channel)
SELECT
l.id AS lead_id,
CURRENT_TIMESTAMP AS date_added,
1 AS reason,
'$channel' AS channel
FROM alpha.leads AS l
WHERE 1
AND l.pr_mktg_{$channel} = 0
AND l.id not in (SELECT dnc.lead_id FROM alpha.lead_donotcontact dnc WHERE dnc.channel = '$channel');Running on small data sets there is no big impact, but as the data grows the impact is obvious. Running on the current test environment, I got 1.1 seconds by running the new approach, as opposed to the current 2.7 seconds.
Running the whole sync script in the test environment:
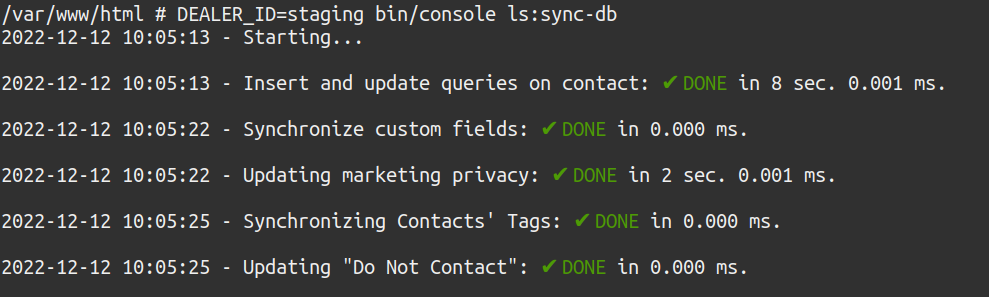
The synchronization script went from 42 seconds down to 10 seconds for achieving the same goal. 4x improvement is not bad at all. Yay! ?
The moment of truth
Few days later, here comes the logs:
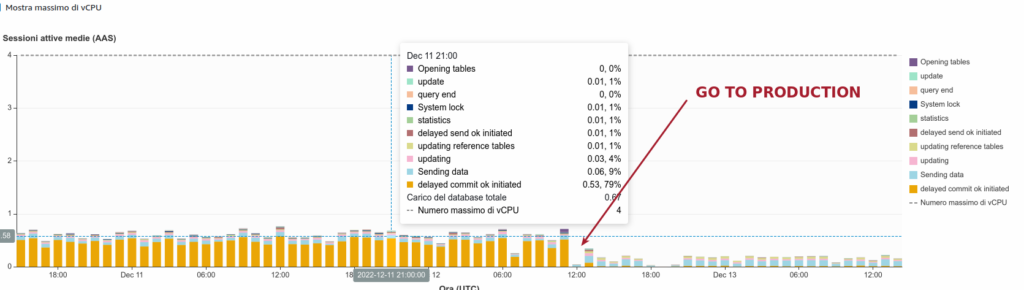
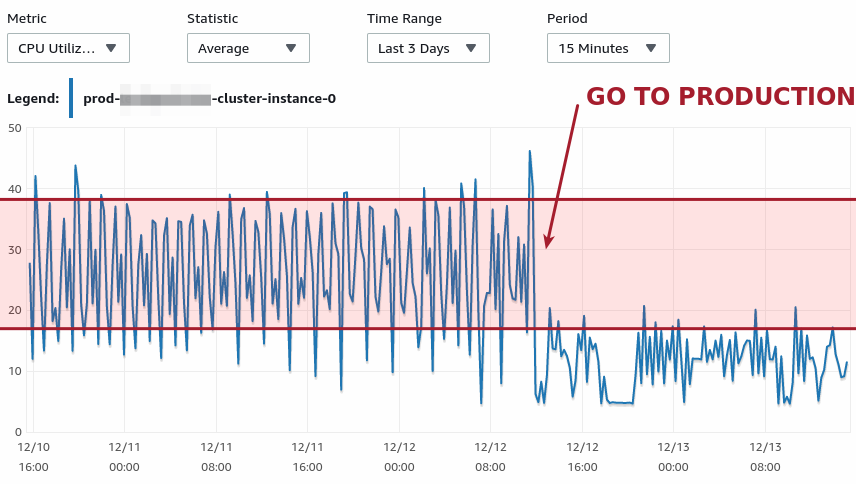
I cannot stress enough how big this is; think about the impact on the long-term. Of course, this does not mean “let’s close this chapter and forget about it”, but rather remember to look closer at your system once in a while.
Fabio, the CTO, says it well:
- ? monitor 5 minutes each day is key: own your system and learn from it
- ? set (and nurture) alerts: DRY
- ?️ act on 1 root problem each time
- ? iterate fast
I’d like to know if you think this script can be optimized even more. More than that, there’s a bug somewhere in these queries – can you spot it? (Ah, the joy of revisiting your own work, by writing articles – you find bugs ?).