The Great Docker Logging Mystery: When 21KB Messages Become 8KB Chunks
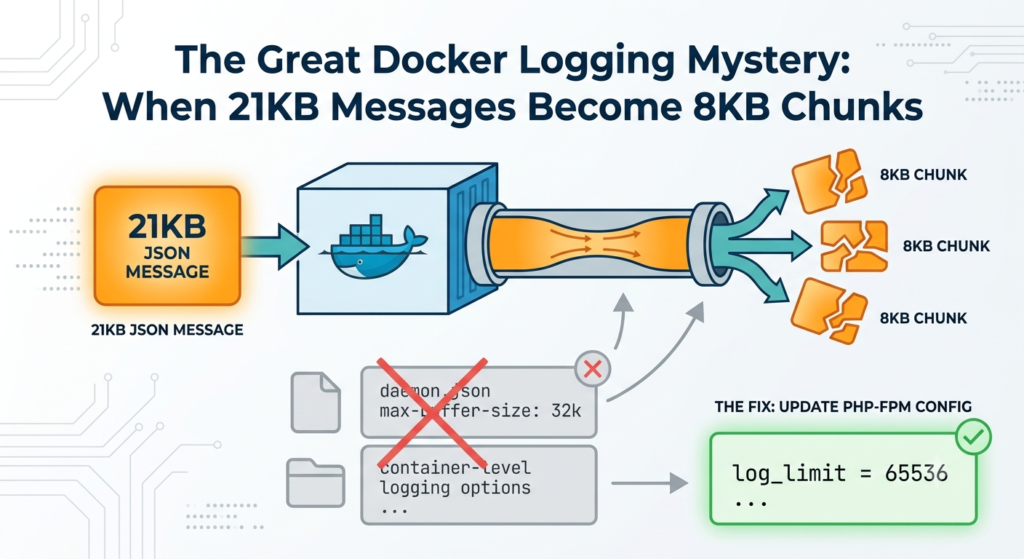
Picture this: You’re monitoring your production logs, everything seems normal, until you notice something odd. Your application is processing large JSON messages—some pushing 21KB—but when you check the Docker logs, they’re mysteriously chopped into neat 8KB pieces. The data is there, but fragmented across multiple log lines, turning your structured logging into a debugging nightmare.
This is the story of how I spent four hours chasing ghosts in the Docker logging pipeline, only to discover the culprit hiding in plain sight in a configuration file I never thought to check. It’s a tale of assumptions, red herrings, and the eventual “aha!” moment that every developer knows and loves.
If you’ve ever dealt with containerized applications that need to log large payloads, this journey might save you some serious debugging time. Spoiler alert: the solution was simpler than I thought, but finding it required questioning everything I assumed about how Docker handles logging.
TL;DR: The Solution
Before we dive into the detective work, here’s what actually fixed the issue:
The Problem: Docker logs were truncating large log messages at exactly 8192 bytes (8KB), splitting them across multiple log entries.
The Root Cause: PHP-FPM’s global log_limit configuration was set to 8192 bytes in /usr/local/etc/php-fpm.d/docker.conf.
The Fix: Override the limit in your PHP-FPM configuration:
[global]
; Override the default of 8192 because we use log scraping from container's runtime stdout/stderr,
; and we need full log lines. Set 64K (65536) as the new value.
log_limit = 65536Now, let’s dive into how I discovered this and all the wrong paths I took along the way.
The Problem: When Big Messages Meet Small Buffers
In our production environment, we run containerized workers that process incoming messages of varying sizes. These messages can range from small 1KB notifications to large 21KB+ data payloads containing complex JSON structures. For debugging and monitoring purposes, we log these entire messages to stdout/stderr so they’re captured by our logging infrastructure.
Everything worked fine with smaller messages, but we started noticing that larger payloads were being split across multiple log entries. Instead of seeing:
{"timestamp": "2025-07-21T11:50:34", "message": "...21KB of JSON data..."}We were getting:
{"timestamp": "2025-07-21T11:50:34", "message": "...first 8KB of JSON...
...second 8KB chunk continues here...
...final chunk with closing braces..."}This fragmentation was breaking our log parsing, making it nearly impossible to reconstruct the original messages for debugging. Time to investigate.
Round 1: Blaming Docker (The Obvious Suspect)
My first instinct was to blame Docker’s logging system. After all, if messages are getting chunked, it must be the logging driver, right? I dove into Docker’s documentation and found references to buffer sizes and logging configurations.
Attempt 1: Configuring Docker Daemon Settings
I started by trying to increase Docker’s logging buffer size. Created ~/.docker/daemon.json on my macOS development machine:
{
"log-driver": "json-file",
"log-opts": {
"mode": "non-blocking",
"max-buffer-size": "32k"
}
}Restarted Docker Desktop, rebuilt my containers, and… nothing. Still getting 8KB chunks.
Attempt 2: Container-Level Logging Configuration
Maybe the daemon-level settings weren’t taking effect. Let me try configuring it per container in docker-compose:
services:
my-service:
logging:
driver: "json-file"
options:
mode: "non-blocking"
max-buffer-size: "32k"Again, no dice. The 8KB limit persisted like a stubborn bug that refuses to be squashed.
Attempt 3: Alternative Logging Drivers
Perhaps the issue was with the json-file driver itself. I experimented with other drivers:
# Tried local driver
services:
my-service:
logging:
driver: "local"
# journald option (candidate)
services:
my-service:
logging:
driver: "journald"
The journald driver redirects logs away from docker logs to journalctl, which isn’t compatible with our existing logging infrastructure, so I did not bother to test. The local driver had similar truncation issues.
At this point, I was starting to question whether Docker was really the culprit.
Round 2: Suspecting PHP-FPM (Getting Warmer)
A breakthrough came when I tested direct command execution versus normal container operation:
# This worked fine - full 21KB message in one line
docker exec -it container_name bin/console my-command-that-produces-long-log-lines
# But this was chunked at 8KB
docker logs container_nameThis was a crucial clue! When using docker exec, the output bypassed Docker’s logging system entirely and went directly to my terminal. But during normal operation, the flow was:
App → stdout → Docker logging driver → docker logs (chunked at 8KB)The fact that docker exec worked suggested the issue wasn’t in my application code, but somewhere in the logging pipeline. Since I’d already ruled out Docker’s logging configuration, the next suspect was PHP-FPM.
Hunting for PHP-FPM Log Limits
I started digging into PHP-FPM configuration, looking for anything related to log limits:
# Check current log_limit setting
docker exec container_name php -r "echo ini_get('log_limit');"Interestingly, this returned an empty value, which should mean “no limit.” But PHP-FPM has its own configuration layer that can override PHP’s settings.
I checked various PHP-FPM pool configurations:
# Look for FPM config files
docker exec container_name find /usr/local/etc -name "*.conf" | grep fpmFound several config files, but none seemed to have obvious logging limits. I was getting frustrated.
Round 3: The Scientific Approach (Isolating Variables)
Time to get systematic. I needed to isolate exactly where the chunking was happening. Was it PHP itself, PHP-FPM, or something else?
Testing PHP CLI vs PHP-FPM
I created a simple test script to bypass PHP-FPM entirely:
#!/usr/bin/env php
<?php
$largeMessage = str_repeat('A', 21000);
fwrite(STDOUT, "STDOUT: " . $largeMessage . "\n");
fwrite(STDERR, "STDERR: " . $largeMessage . "\n");
echo 'done.' . PHP_EOL;
Then ran it as a standalone container:
services:
test-php:
image: my-php-image
entrypoint: php
command: test-script.phpThe result? Full 21KB messages, no chunking! This confirmed that PHP itself wasn’t the problem—it was definitely something in the PHP-FPM layer.
Comparing with Working Systems
I remembered that we had Java applications in our Kubernetes cluster that successfully logged large messages without chunking. This suggested that the container runtime (containerd/Docker) itself wasn’t imposing the 8KB limit—it was specific to our PHP-FPM setup.
Round 4: The “Aha!” Moment (Finding the Smoking Gun)
After hours of debugging, I decided to systematically examine every PHP-FPM configuration file in our Docker image. That’s when I stumbled upon /usr/local/etc/php-fpm.d/docker.conf:
[global]
error_log = /proc/self/fd/2
; https://github.com/docker-library/php/pull/725#issuecomment-443540114
log_limit = 8192
[www]
; php-fpm closes STDOUT on startup, so sending logs to /proc/self/fd/1 does not work.
; https://bugs.php.net/bug.php?id=73886
access.log = /proc/self/fd/2
clear_env = no
; Ensure worker stdout and stderr are sent to the main error log.
catch_workers_output = yes
decorate_workers_output = noTHERE IT WAS! log_limit = 8192
That innocent-looking line was the source of all my troubles. This configuration, included in the official Docker PHP images, was specifically designed to prevent log flooding by limiting individual log entries to 8192 bytes (8KB).
The comment even referenced a GitHub issue about this exact behavior. The Docker PHP maintainers had intentionally set this limit to prevent runaway logging from crashing systems, but it was exactly what was breaking my use case.
The Fix: Simple Yet Effective
Once I found the culprit, the fix was straightforward. I created an override in my PHP-FPM configuration:
[global]
; https://github.com/docker-library/php/pull/725#issuecomment-443540114
; Override the default of 8192 because we use log scraping from container's runtime stdout/stderr,
; and we need full log lines. Set 64K (65536) as the new value.
log_limit = 65536Why 64K? My largest messages were around 21KB, so 64K (65,536 bytes) provided comfortable headroom for future growth while still maintaining some reasonable upper bound.
After rebuilding the container with this configuration, my 21KB messages flowed through the logging pipeline intact—no more chunking, no more fragmented JSON structures.
Verification: Proving the Fix Works
To verify the fix, I ran my test script again:
# Generate a 21KB message and log it
docker logs my-container | grep "test-message" | wc -c
# Result: 21504 bytes - perfect!The large messages now appeared as single, complete log entries in both docker logs and our centralized logging system.
Why This Was So Hard to Find
Looking back, several factors made this issue particularly tricky to diagnose:
1. Invisible Configuration
The log_limit setting was buried in a configuration file that I never expected to check. It wasn’t in the main php.ini or the obvious PHP-FPM pool configuration—it was in a Docker-specific config file.
2. Misleading Symptoms
The 8KB chunking seemed like a Docker logging issue, not a PHP-FPM configuration problem. The exact 8192-byte boundary was the only clue that led me in the right direction.
3. Hidden Dependencies
The issue only manifested when using PHP-FPM with specific logging configurations. CLI PHP scripts worked fine, and other language runtimes (Java) didn’t exhibit the problem.
Alternative Solutions I Considered
Before finding the root cause, I explored several workarounds:
Application-Level Chunking
This approach wasn’t as straightforward as it initially seemed. While it would prevent the arbitrary 8KB cuts, it introduced several complications:
- Multi-line fragmentation: Instead of clean JSON objects, we’d have intentionally split log messages across multiple lines
- Scraper complexity: Our log scraping infrastructure would need significant modifications to piece together all the numbered chunks, otherwise (see next point)
- Human readability: Debugging would become much harder since you’d never see the complete message in a single log entry—you’d always need to mentally (or programmatically) reconstruct the full payload
Structured Logging with Message IDs
This was a more elegant version of chunking, but suffered from similar issues as the application-level approach:
- Ordering concerns: In high-throughput scenarios, there’s no guarantee that chunks arrive in order, especially across different log streams
- Reconstruction overhead: The log scraper would need to buffer partial messages and wait for all parts before processing, otherwise (see next point)
- Debugging nightmare: Trying to trace a specific message would require correlating multiple log entries by message ID—not exactly developer-friendly
External Logging
Instead of relying on Docker’s stdout/stderr capture, we could bypass the logging pipeline entirely by writing directly to mounted log files.
This was actually the most viable workaround and could have worked well since we already use this pattern for some applications. However, it would have required significant infrastructure changes:
- Deployment modifications: Every service deployment would need to be reconfigured with sidecar log scrapers instead of our existing stdout/stderr collection
- Operational overhead: Managing file-based logging means dealing with log rotation (easy with monolog), disk space monitoring, and file permission issues
- Consistency concerns: We’d end up with a mixed logging architecture—some services using stdout/stderr and others using file-based logging
While these approaches would have technically solved the chunking problem, they all felt like elaborate workarounds rather than actual solutions. Each introduced additional complexity into either our application code or our infrastructure, when the real issue was a simple configuration setting.
Key Lessons Learned
This debugging adventure taught me several valuable lessons:
1. Question Your Assumptions
I initially assumed the problem was in Docker’s logging system because that’s where the symptoms appeared. But the actual issue was several layers deeper in the stack. Always be willing to challenge your initial hypothesis.
2. The Machines Are Never Wrong
When you see consistent, reproducible behavior (like exact 8KB chunking), there’s always a logical explanation. The computer isn’t randomly deciding to split your logs—something is programmatically enforcing that limit.
3. Test in Isolation
Creating the standalone PHP CLI test was crucial for isolating the problem. By removing PHP-FPM from the equation, I could prove that PHP itself wasn’t the issue.
4. Read the Fine Print
Configuration files often contain comments with links to relevant issues or documentation. That GitHub link in the PHP-FPM config was a goldmine of context about why the setting existed.
5. Default Configurations Have Opinions
The Docker PHP images made a reasonable default choice to prevent log flooding, but defaults don’t always match your specific use case. Always review what your base images are configuring for you.
Beyond the Fix: Production Considerations
While increasing the log_limit solved my immediate problem, it’s worth considering the broader implications:
Performance Impact
Larger log entries mean more memory usage and potentially slower log processing. Monitor your logging infrastructure to ensure it can handle the increased payload sizes.
Log Rotation
With larger individual log entries, your log rotation policies might need adjustment to prevent disk space issues.
Parsing Complexity
Make sure your log parsing tools can handle the larger entries efficiently. What works for 8KB messages might not scale to 64KB entries.
Conclusion
What started as a mysterious Docker logging issue turned into a deep dive through the containerized application stack. Four hours of debugging led me from Docker daemon configurations through alternative logging drivers to the eventual discovery of a single configuration line that was causing all the trouble.
This experience reinforced one of the fundamental principles of debugging: when dealing with complex systems, the issue is rarely where you first think it is. It’s often hiding in the layer you least expect, waiting to be discovered by systematic investigation and a willingness to question your assumptions.
The next time you encounter mysterious behavior in your containerized applications, remember to look beyond the obvious suspects. That innocent-looking configuration file might be hiding the key to solving your problem.
Found this debugging journey helpful? Follow me for more deep dives into the mysteries of containerized applications and the occasional “WTF” moments that make development interesting. Got your own Docker logging horror stories? Share them in the comments—we all learn from each other’s debugging adventures.